
システムのインフラ(start.bat)とファイル構成が整理できたところで、いよいよ本ツールの心臓部であるメインプログラム kindle_auto.py の深淵に入っていきましょう。
何百ページもある電子書籍を、人間が一度もマウスやキーボードに触れることなく、1ピクセルの狂いもなく全自動でPDF化する。これを実現するためには、単に「スクリーンショットを撮る」だけでは不十分です。
まずは、僕がこのコードを書くにあたって最上位に置いた「設計思想(コンセプト)」から解説し、その後、最大の難関であった「境界線の動的判定アルゴリズム」などの技術的急所を紐解いていきます。
5. 全体仕様と設計コンセプト:「人間への非依存」と「OSレベルの確実性」
kindle_auto.py の根底にあるPM的な設計コンセプトは、「ヒューマンエラーの排除(ゼロ・コンフィグ)」と「環境差異の吸収」です。
既存のツールでは、ユーザーが事前に「座標の指定」「総ページ数の入力」「右綴じ・左綴じの選択」を行う必要がありました。しかし、これらは全てプログラム側で動的に解決すべき課題です。
このコンセプトを実現するため、スクリプト全体を以下のワークフローで構築しています。
| ステップ | 処理フェーズ | 内部で行っている「自動化」の論理 |
| 1. 初期化 | ウィンドウの捕捉とDPI対応 | OSのAPI(ctypes)を叩き、他アプリの裏に隠れたKindleを強制的に最前面へ引きずり出します。同時に、ディスプレイの拡大縮小設定(150%など)による座標ズレを防ぐ宣言を行います。 |
| 2. 表紙解析 | 境界線の動的取得 | 全画面化(F11)後、最初のページ(表紙)を撮影し、背景色とコンテンツの境目をピクセル単位で自動算出します。 |
| 3. 方向判定 | めくりキーの自動決定 | 「左キー」を試し打ちして画面が変わるか(右綴じか左綴じか)をプログラム自身に判断させます。 |
| 4. ループ | 無間断キャプチャ | 以降、総ページ数を知らなくても、ひたすら「めくって、解析して、切って、保存」を繰り返します。 |
| 5. 終了検知 | Auto-Stop処理 | 取得した画像が「前のページと実質同じ」になった瞬間を検知し、安全にループを抜け、PDF結合へ移行します。 |
6. アルゴリズムの核心:境界線の動的判定(Center-Outward Scan)
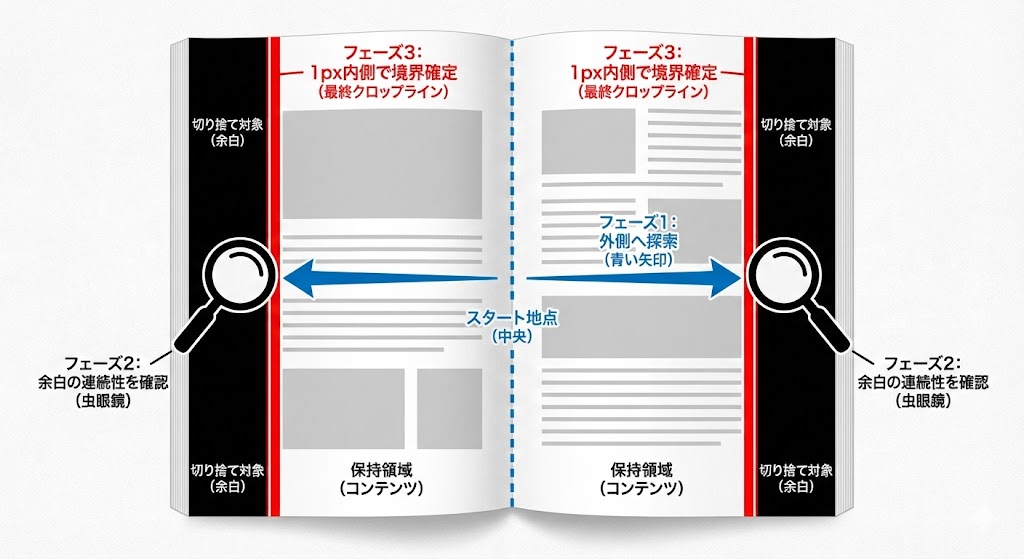
このプログラムの中で最も複雑で、かつ僕が執念を燃やしたのが境界判定アルゴリズムです。
「背景が真っ白な小説」から「背景が真っ黒な漫画」まで、あらゆるパターンにおいて余白を完璧に切り落とすため、「垂直カラム・プロファイリングと中央-外側探索法」というアプローチを採りました。
課題:背景に潜む罠
単純に「真っ黒や真っ白の領域があれば背景領域だ」と判定すると判断を誤ります。
Kindle では背景色をたとえ白やセピアに設定していても、漫画や写真集のような本の場合は、自動的に背景色が黒色になります。
また黒色といっても全領域が黒色ではなく、上端や下端に白い部分が残っていたりなどします。
他にも、背景色のさらに両端にページ送りのための領域があり、その領域の色がまた背景色と異なっていたりします。
解決策と判定の3フェーズ
これを解決するため、以下のような厳密なロジックを組んでいます。
Phase 0: サンプリング範囲の制限(ノイズカット)
Python
# 縦方向: 上端・下端この行数は境界判定から除外
CONTENT_VERTICAL_EDGE_SKIP = 2
# --- find_content_width_center_out 関数内の抜粋 ---
w, h = img.size
# 上下端の数行は白ドットになりやすいため除外(黒余白が active と誤判定されないようにする)
skip = CONTENT_VERTICAL_EDGE_SKIP
if h <= skip * 2:
sample_ys = list(range(h))
else:
# ここが急所:Y座標のサンプリング範囲を [2] から [高さ - 2] に制限する
sample_ys = list(range(skip, h - skip))
def column_is_active(x):
"""描画データがある(アクティブな)縦線かを判定する内部関数"""
if x < 0 or x >= w:
return False
has_black, has_white, has_other = False, False, False
# 全Y座標ではなく、上下端を切り落とした制限リスト(sample_ys)のみを走査する
for y in sample_ys:
p = pix[x, y]
if _is_near_black(p):
has_black = True
elif _is_near_white(p):
has_white = True
else:
has_other = True
# 「黒と白が混在」または「それ以外の色(グレー等)がある」場合にアクティブ(描画あり)と判定
return bool(has_other or (has_black and has_white))意図的に画面の上下2ピクセルを「見ない」ようにすることで、システム由来のノイズを完全に無視します。
Phase 1: 中央から外側への粗探索
画面の中央X座標から、左右へ向かって SCAN_STEP_PX(既定20px)刻みで「アクティブな列(文字や絵がある列)」を探します。
Phase 2: マージンの連続性確認(PM的「疑い」の実装)
外側へ進み、最初に「背景色(マージン)だけの列」が見つかったとします。しかし、そこですぐに境界と断定しません。「それはただの文字間の空白かもしれない」からです。 そこで、「その列からさらに外側へ20列連続で背景色が続いているか」を確認し、真の余白であることを確定させます。
Phase 3: 内側への1px精密走査
真の余白列が確定したら、そこから「中央方向(内側)へ」1ピクセルずつ戻るように走査します。最初にコンテンツのピクセルにぶつかった位置が、究極の境界線となります。
最後に、左右で見つかった半幅のうち「大きい方」を採用し、常に中央対称の美しいレイアウトになるよう補正してクロップします。
7. アルゴリズムの補助線:終了の自動検知(Auto-Stop)
もう一つの重要アルゴリズムが、images_effectively_same 関数による終了検知です。
「最後のページまで来たら止まる」を人間が指示するのではなく、画像比較で実現します。しかし、単純な完全一致(ハッシュ値の比較など)では、KindleのUIの微小なちらつき(フリッカー)のせいで「違うページだ」と誤認し、無限ループに陥ります。
Python
# 同一ページ判定: 差がこの割合以下なら「同じページ」とみなす
SAME_PAGE_DIFF_RATIO = 0.005
# 同一ページ判定: この値より大きい差があるピクセルは「変化」とみなす
SAME_PAGE_PIXEL_THRESHOLD = 12
def images_effectively_same(img1: Image.Image, img2: Image.Image) -> bool:
"""
2画像が実質同じか(ページが変わっていないか)。
完全一致でなく、変化ピクセルが SAME_PAGE_DIFF_RATIO 以下なら同一とみなす。
"""
if img1.size != img2.size:
return False
a = img1.convert("RGB")
b = img2.convert("RGB")
w, h = a.size
# 全ピクセルは重いので、間引きしてサンプル比較(約 1/16)
step = 4
different = 0
threshold = SAME_PAGE_DIFF_RATIO # 0.005 (0.5%)
px_th = SAME_PAGE_PIXEL_THRESHOLD # 12
pa, pb = a.load(), b.load()
for y in range(0, h, step):
for x in range(0, w, step):
r1, g1, b1 = pa[x, y]
r2, g2, b2 = pb[x, y]
# ピクセルごとの色の差が閾値(12)を超えているか?
if abs(r1 - r2) > px_th or abs(g1 - g2) > px_th or abs(b1 - b2) > px_th:
different += 1
# 比較した全ピクセル数の算出
sampled = ((w + step - 1) // step) * ((h + step - 1) // step)
# 変化したピクセルの割合が 0.5% 以下であれば「同じページ」と判定
return (different / sampled) <= thresholdここでもPM的な閾値設定を行っています。 画像を高速化のために間引き(1/16にサンプリング)した上で、「RGBの差が12より大きいピクセル」が「全体の0.5%以下」であれば、「人間には同じページに見えている(=これ以上めくれない終端に達した)」と判断し、安全にキャプチャを終了させるロジックです。


コメント